其实在这两款产品之前,Intel的Xeon Phi产品中就已有SE10P和SE10X两款,而且这两款产品目前已经用在了TACC德克萨斯高级计算中的Stampede超级计算机上,因为它们还是测试样品,所以Intel给出的价格极具诱惑力,每块只有400美元,当然实际产品售价在2000美元以上。
Anandtech网站又对TACC所用的Xeon Phi做了一番解析,来了解一下Xeon Phi到底有什么秘密吧。

Xeon Phi品牌其实早在6月份就宣布过了,不过直到现在才有详细的信息。从核心图上看,它的MIC内核总计有50亿个晶体管,甚至比安腾9500系列还多,幸好有了22nm 3D晶体管,不然制造这样大规模的芯片可不容易。
每个核心最多有62个内核,512位SIMD阵列,每个核心都是一个X86架构的顺序指令体系的微内核,来源于原始的Pentium,看起来跟Atom有些相似。
虽然是顺序指令体系,不过每个内核可以执行4个同步线程,而Nehalem之后的Intel处理器大都也支持SMT多线程,不过他们支持多线程只是为了更好地利用执行资源。
在Xeon Phi中,4线程更可能是一种隐藏(hide)内存延迟的方法,最好的情况下并行处理也只有2条线程而已。
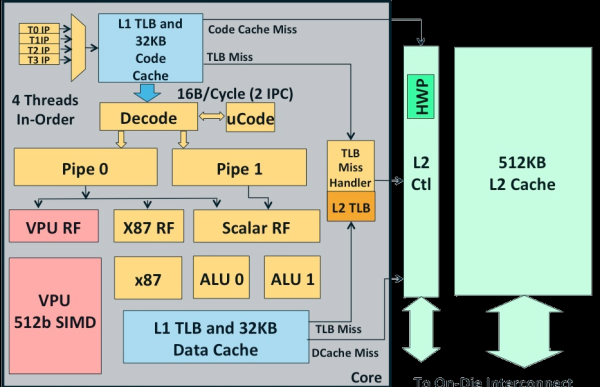
每个内核都是一个64位X86核心,不过只有2%的逻辑电路(包括L2缓存在内)是用于X86的,Xeon Phi的SIMD不支持MMX、SSE及AVX指令,它有自己的矢量格式。
所有内核都是通过一个双向环形总线连接的,类似于Intel在Xeon E7及SNB-EP处理器中用过的那样。
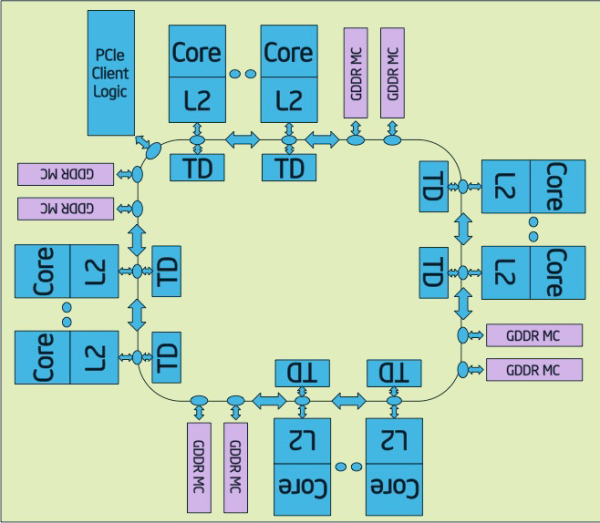
Xeon Phi有8条内存通道,位宽512-bit,支持8GB GDDR5内存,并整合了PCI-E控制器。
Xeon Phi卡规格
Xeon Phi使用PCI-E接口,看起来像是一块显卡,不过该架构最早就是面向GPU应用的,所以以显卡的形式出现也没什么意外的。而且跟其他加速卡一样,Xeon Phi也没有显示输出接口,它纯粹就是一个计算卡。
Xeon Phi运行的是开源的、经过修改的Linux系统,每个Xeon Phi卡都有自己的IP地址,但是它不能独立运行,还需要搭配CPU使用,也就是说正常版的Xeon依然是作为主处理器,Xeon Phi的作用跟AMD/NVIDIA的GPU加速卡类似,不能独立使用。
下面是Intel的Xeon Phi卡的规格。
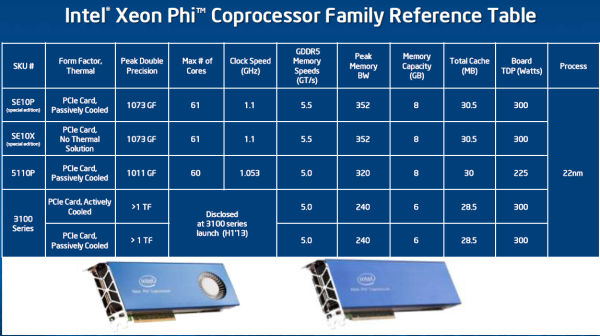
TACC的Stampede超级计算机使用的Xeon Phi是特定的版本,有61个内核,频率也略微提高到1.1GHz。正常商用的的5110P是60个内核,频率也低了50MHz,实际频率为1.053GHz,同样搭配8GB GDDR5 ECC内存。5110P名称中的P后缀意味着它是被动散热的,主要依赖主机的散热系统。
另外,5110P 2699美元的价格不算便宜,不过相比NVIDIA Tesla K20的3199美元报价还算适当,其主要优势在于超高的带宽,51bit内存位宽、5GHz频率下总带宽达到320GB/s,高于K20及K20X。
明年年中才会发布的3110系列售价低于2000美元,搭配6GB GDDR5内存,5GHz频率,位宽也缩减到384bit,不过核心频率可能会略有提高,可提供超过1TFLOPS的双精度浮点性能。
另外,Xeon Phi的PCI-E虽然是2.0标准,但是频率为7GHz,要高于PCI-E 2.0正常的5GHz,因为Intel发现升级到PCI-E 3.0标准会导致代价过高,所以才有这个折衷方案。
TACC中心的Stampede计算机
位于TACC中心的Stampede计算机是世界上第一款使用Xeon Phi架构的超级计算机,它由6400个戴尔PowerEdge C8220X及C8220服务器机柜组成,每个服务器包含2个8核Xeon E5处理器,32GB内存以及一块Xeon Phi加速卡。

每间房子里有并排放置的2个C8000 4U机柜,每个机柜内有8个PowerEdge服务器。

这些服务器通过FDR无限连接技术连接成为一个超级计算机。
先期组建的Xeon E5部分可以通过2PteaFlips(千万亿次)的能力,使用Xeon Phi之后还可以提供额外的8PetaFlops计算能力。
不过Xeon Phi还不能完全取代GPU,因为它没有纹理单元,所以这台计算机的远程虚拟化功能是由128个NVIDIA Tesla K20加速卡完成的。
Stampede的其他部分还有272TB容量的内存,14PB的存储容量。整个计算机及冷却系统总计需要600万瓦的电力供应。
Xeon Phi的编程特性
Xeon Phi的一大吸引力就是它可以直接运行为Xeon编写的多线程代码。为了更好地发挥Xeon Phi的性能,开发者可以使用Intel C或者Fortan的编译器来运行代码。这样一来,Intel宣称在Xeon Phi上运行典型的应用性能都可以提高2-2.5倍,部分应用提升幅度还会更多。

不过Xeon Phi也不是没有问题,相比较而言,目前廉价的四核解决方案更有效率。在Intel E5架构之前,AMD凭借廉价的四核处理器在HPC市场已经获得不小的成功。对比这样的廉价四核解决方案与Intel主推的CPU+Xeon Phi方案的每瓦性能、每美元性能就会很有趣了。
重点是Xeon Phi编程花费的时间要比NVIDIA的Tesla K20要少得多,虽然后者的CUDA环境已经日趋成熟,不过还是能听到不少厂商抱怨CUDA下的debug太麻烦。而对Intel来说,良好的编译器支持、通用的高性能软件是Xeon Phi的一大优势。
总之,Xeon Phi更具弹性,因为它本质上还是一个通用的Xeon内核,而GPU加速方案主要用于极限的并行环境,因为后者通常都有数百个流处理器。
目前还不能对Xeon Phi作出最终判断,因为Anandtech目前还没有拿到实卡测试,他们对Xeon Phi的第一印象就是它可以做为一个低成本、易使用的HPC解决方案。

游客 2012-11-16 17:50
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
4#
游客 2012-11-15 18:24
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
3#
游客 2012-11-15 18:24
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
2#
游客 2012-11-15 16:57
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
1#