
Intel在HotChips会议上公布了Xeon Phi的详细架构

Xeon Phi使用的是Intel MIC多核架构,后者与已经挂掉的Larrabee架构有莫大的关系,Intel原本想用精简的X86核心做GPU的,不过未能成功,反倒无心插柳将其变成了专司高性能计算的Xeon Phi。
Xeon Phi使用的是一个512bit SIMD体系,支持X86指令集以及通用的Linux平台、Fortan、C、C++等语言。
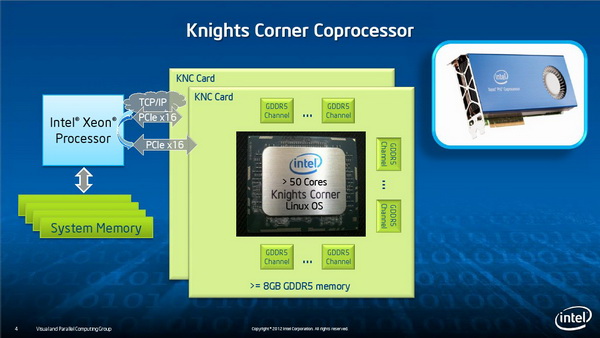
架构优势

Intel强调Xeon Phi的一大优势就是高效,TOP500中排名150位的HPC使用的就是Xeon Phi处理器,功耗为72.9KW,排名177的使用是NVIDIA Tesla 2090,功耗为81.5KW,使用AMD Radeon的HPC虽然功耗只有47KW,但是排名456位,性能不济。
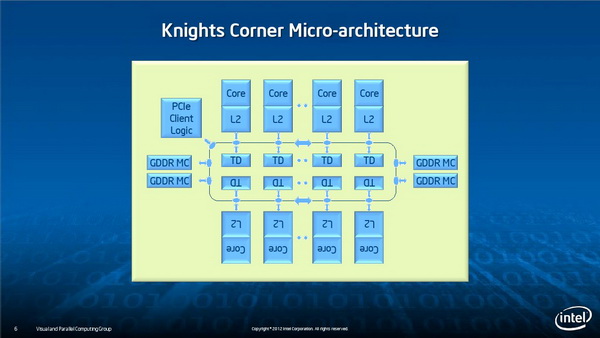
Xeon Phi既然名为MIC超多核,那么每个内核的能力势必不可能跟单一Xeon品牌的内核相当,不过MIC强调的是大规模并行计算,核心规模50+,现有的工艺已经生产出61个核心的产品了,所以总体计算能力更强。
内核体系
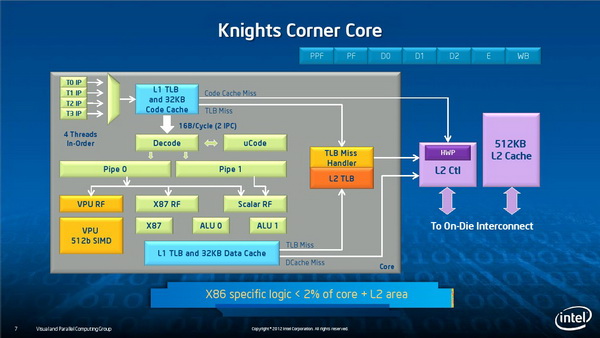
每个内核有32KB L1代码缓存,并有一个512bit矢量单元和2个超标量单元,L2缓存则有512KB,实际上L2缓存要比桌面版处理器还要高,目前Ivy Bridge的每个内核L2缓存也不过256KB,Intel希望通过增大Xeon Phi内核的L2缓存来提升其超大规模运算能力。
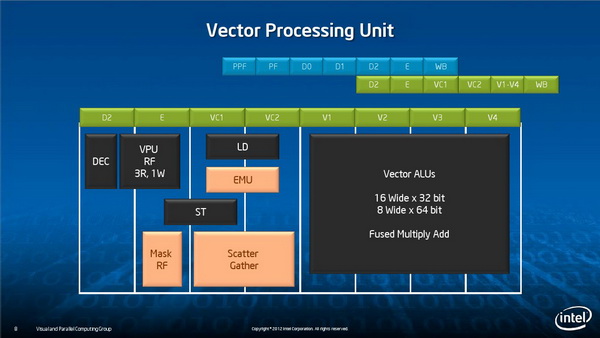
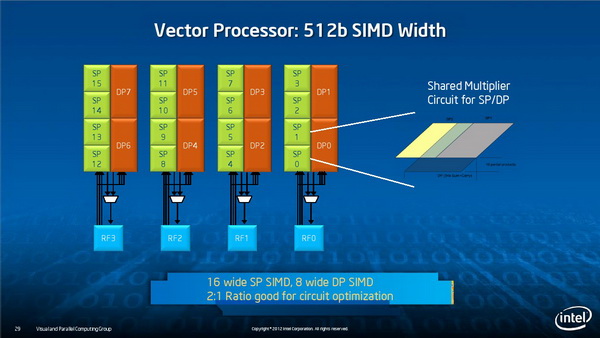
矢量单元设计
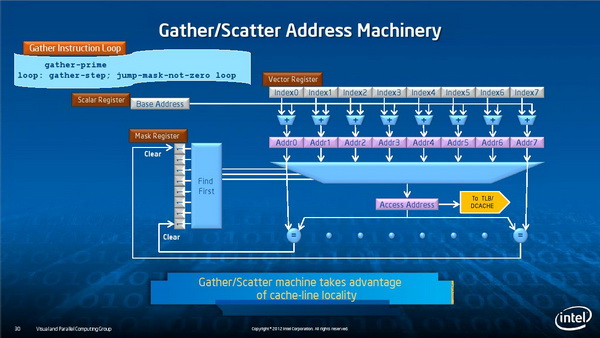
内核及内存的互联
如此庞大的内核规模必然面临一个重要问题:每个内核要如何连接起来。Xeon Phi使用了一种新的内核互联及内存子系统,Intel高级工程师George Chrysos表示这是一种新的环形拓扑总线,不仅用于内核互联,而且也用在了内核与GDDR5显存的连接上。
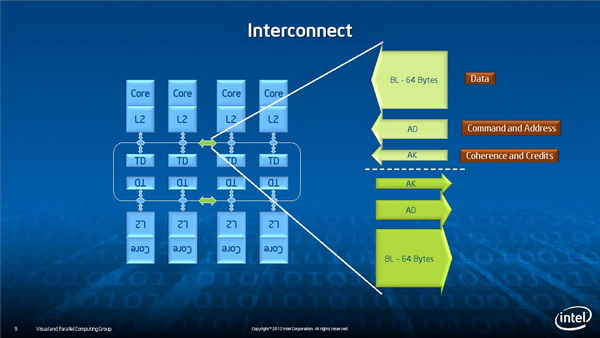
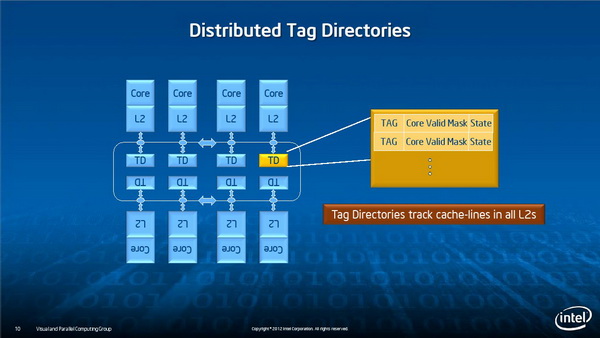
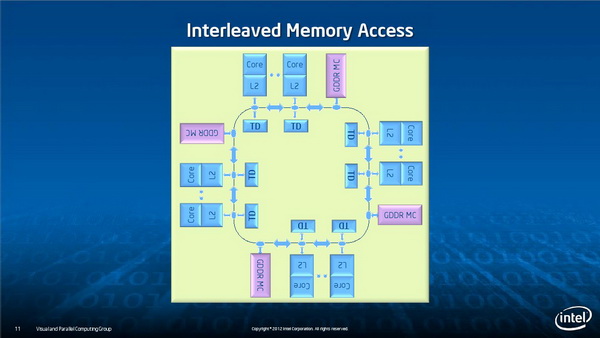
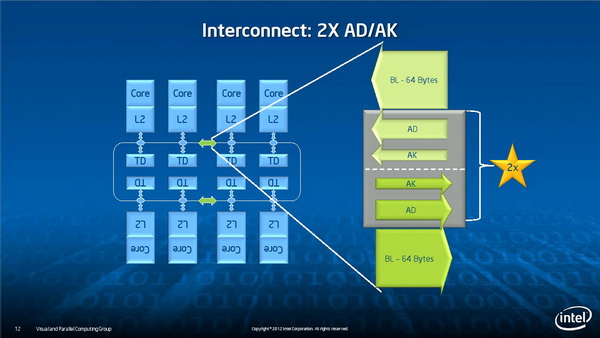
多线程并行
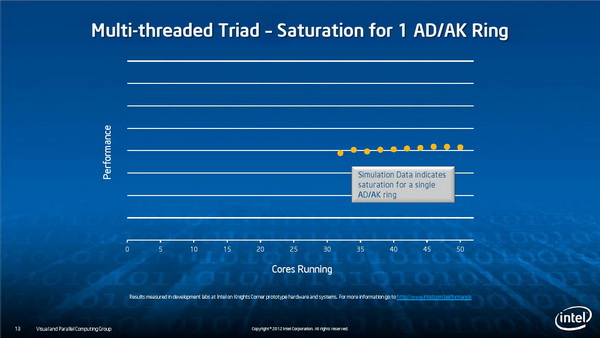
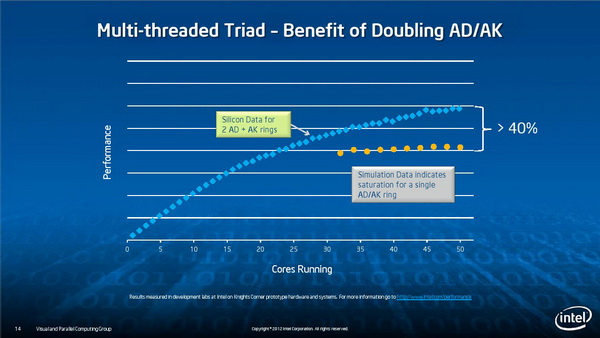

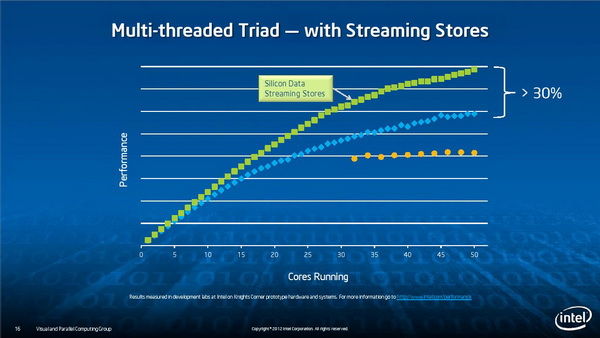

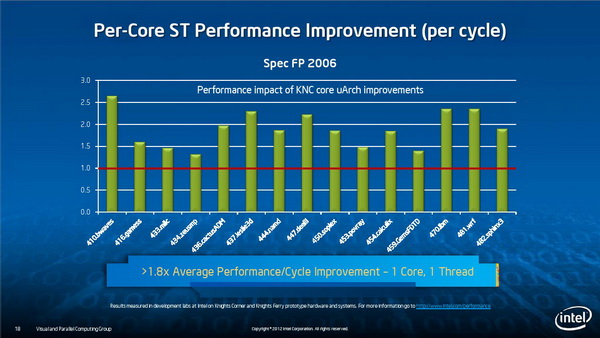
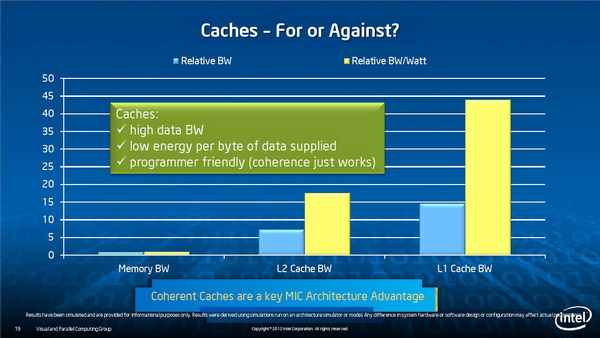

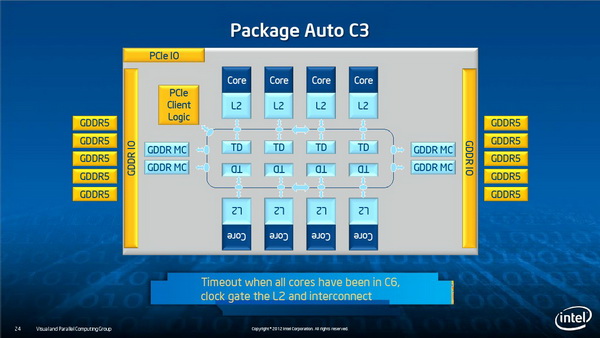
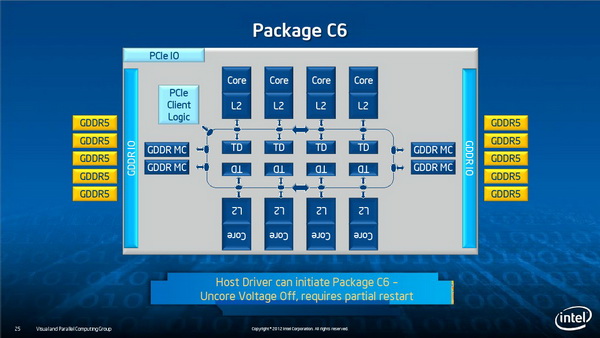
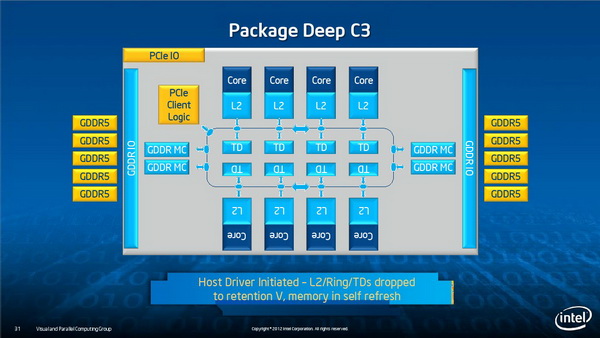
功耗管理
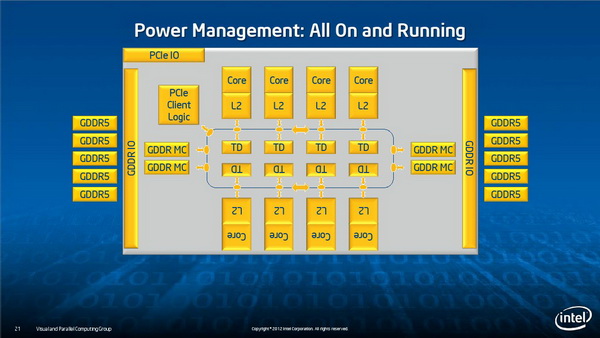
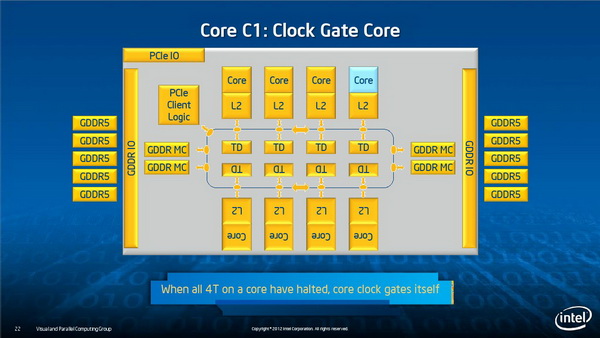
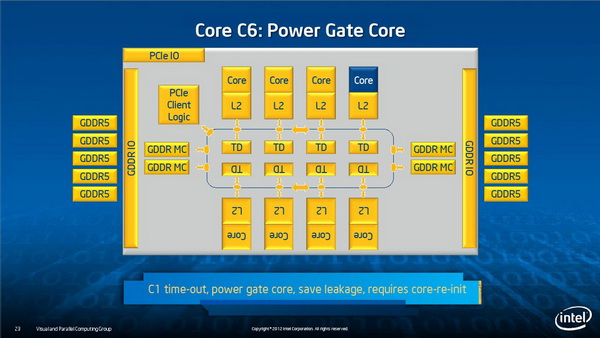




超能网友博士 2012-09-05 09:37 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
5#
游客 2012-09-03 00:08
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
4#
游客 2012-09-02 16:32
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
3#
超能网友一代宗师 2012-09-01 23:36 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
2#
游客 2012-09-01 12:18
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
1#